Project #3: Multimodal Content Understanding and Generation
This project is a collaboration with ARC Lab, Tencent PCG.
The aim of this project is to investigate the understanding, generation, and editing methods of multimodal content. With the development of the internet, the number of digital content creations based on multimodality is showing an exponential growth trend, and more and more people are transitioning from being mere content receivers to creators. However, the massive increase in content creation has not led to a significant improvement in the quality of the creations. This is particularly evident in algorithm-driven automated digital content generation, where there are clear shortcomings in aspects such as theme understanding, content presentation, and layout.
In existing methods of multimodal content generation, design materials are primarily derived from extracting relevant segments from long videos, which are then processed in a simplistic manner. This technology can only handle scenarios with a single theme, and is incapable of understanding the multi-themed content in various segments of the video at a granular level. Moreover, extracting a single segment from a single video also falls short in adequately showcasing the rich semantic information of multimodal content. Consequently, it fails to effectively attract users.
Given the provided design materials, existing editing methods primarily focus on solving static, flat editing problems based on a limited number of elements. For instance, they determine the position and size of text when given a background image and several text segments. However, these techniques do not take into account more complex editing scenarios, such as incorporating diverse design elements like vector graphics or character cutouts. Furthermore, they are unable to handle dynamic design situations with a time dimension, such as editing dynamic video covers.
In response to the shortcomings of current multimodal content generation and editing technologies, we propose a framework for understanding, generating, and editing multimodal content based on fine-grained semantic labels. First, we generate detailed, time-stamped semantic labels by understanding video content, which can then be used for comprehending multimodal content and quickly retrieving materials. Building upon this foundation, we combine the specific design content and presentation scenarios, along with the guidance of aesthetic principles, to edit diverse design elements. Ultimately, this approach enables the creation of digital content that is semantically rich, logically laid out, and features dynamic animation effects.
The entire project can be divided into two research directions, i.e., multimodal content understanding and multimodal content generation, consisting of the following four works:
Multimodal Content Understanding:- UMT: Unified Multi-modal Transformers for Joint Video Moment Retrieval and Highlight Detection (CVPR 2022)
- E.T. Bench: Towards Open-Ended Event-Level Video-Language Understanding (Under Review)
- Toward Human Perception-centric Video Thumbnail Generation (ACM MM 2023)
- PosterLLaVa: Constructing a Unified Multi-modal Layout Generator with LLM (Under Review)
UMT: Unified Multi-modal Transformers for Joint Video Moment Retrieval and Highlight Detection
[arXiv] [Code] [Poster]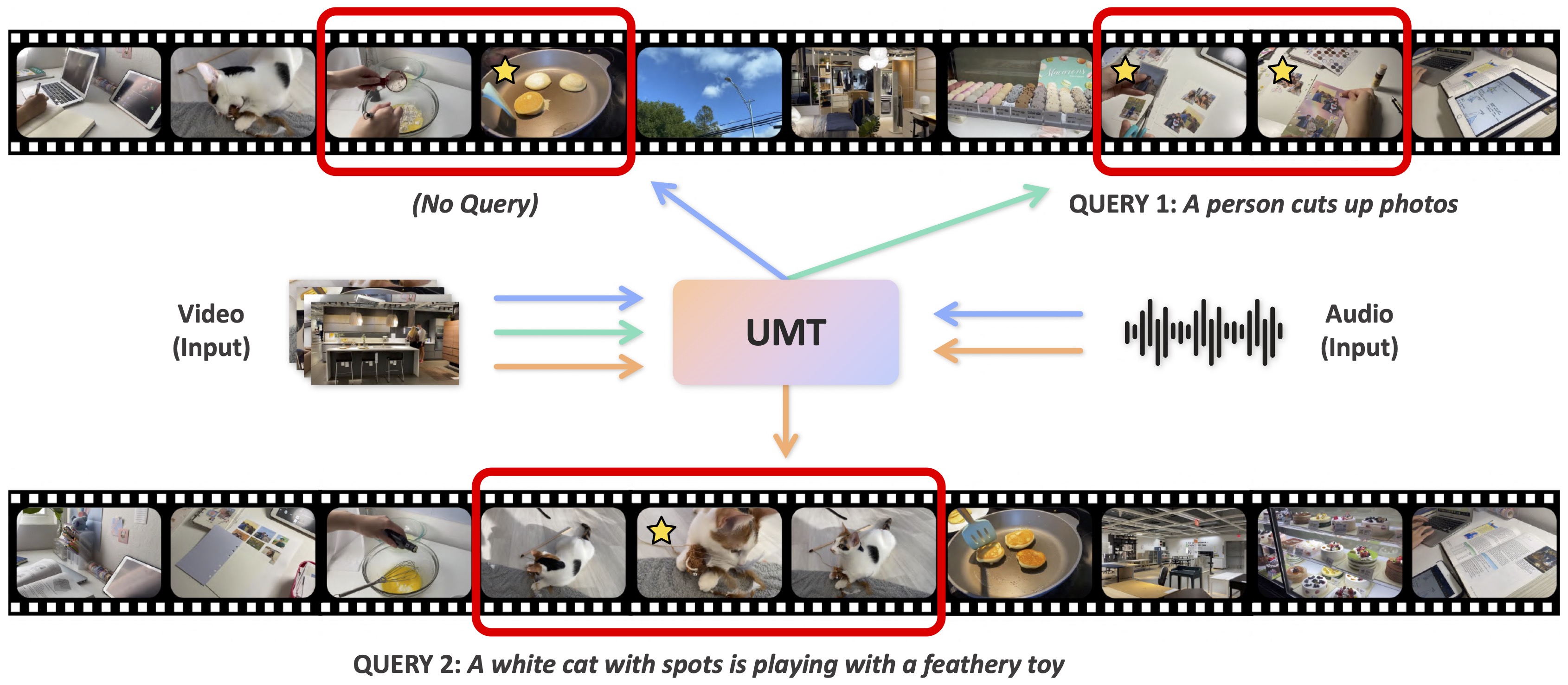
Finding relevant moments and highlights in videos according to natural language queries is a natural and highly valuable common need in the current video content explosion era. Nevertheless, jointly conducting moment retrieval and highlight detection is an emerging research topic, even though its component problems and some related tasks have already been studied for a while. In this paper, we present the first unified framework, named Unified Multi-modal Transformers (UMT), capable of realizing such joint optimization while can also be easily degenerated for solving individual problems. As far as we are aware, this is the first scheme to integrate multi-modal (visual-audio) learning for either joint optimization or the individual moment retrieval task, and tackles moment retrieval as a keypoint detection problem using a novel query generator and query decoder. Extensive comparisons with existing methods and ablation studies on QVHighlights, Charades-STA, YouTube Highlights, and TVSum datasets demonstrate the effectiveness, superiority, and flexibility of the proposed method under various settings.
E.T. Bench: Towards Open-Ended Event-Level Video-Language Understanding
[Project Page]
Recent advances in Video Large Language Models (Video-LLMs) have demonstrated their great potential in general-purpose video understanding. To verify the significance of these models, a number of benchmarks have been proposed to diagnose their capabilities in different scenarios. However, existing benchmarks merely evaluate models through video-level question-answering, lacking fine-grained event-level assessment and task diversity. To fill this gap, we introduce E.T. Bench (Event-Level & Time-Sensitive Video Understanding Benchmark), a large-scale and high-quality benchmark for open-ended event-level video understanding. Categorized within a 3-level task taxonomy, E.T. Bench encompasses 7.8K samples under 12 tasks with 7.7K videos (266.3h total length) under 8 domains, providing comprehensive evaluations. We extensively evaluated 9 Image-LLMs and 10 Video-LLMs on our benchmark, and the results reveal that state-of-the-art models for coarse-level (video-level) understanding struggle to solve our fine-grained tasks, e.g., grounding event-of-interests within videos, largely due to the short video context length, improper time representations, and lack of multi-event training data. Focusing on these issues, we further propose a strong baseline model, E.T. Chat, together with an instruction-tuning dataset E.T. 164K tailored for fine-grained event-level understanding. Our simple but effective solution demonstrates superior performance in multiple scenarios.
Toward Human Perception-centric Video Thumbnail Generation
[Link] [Code]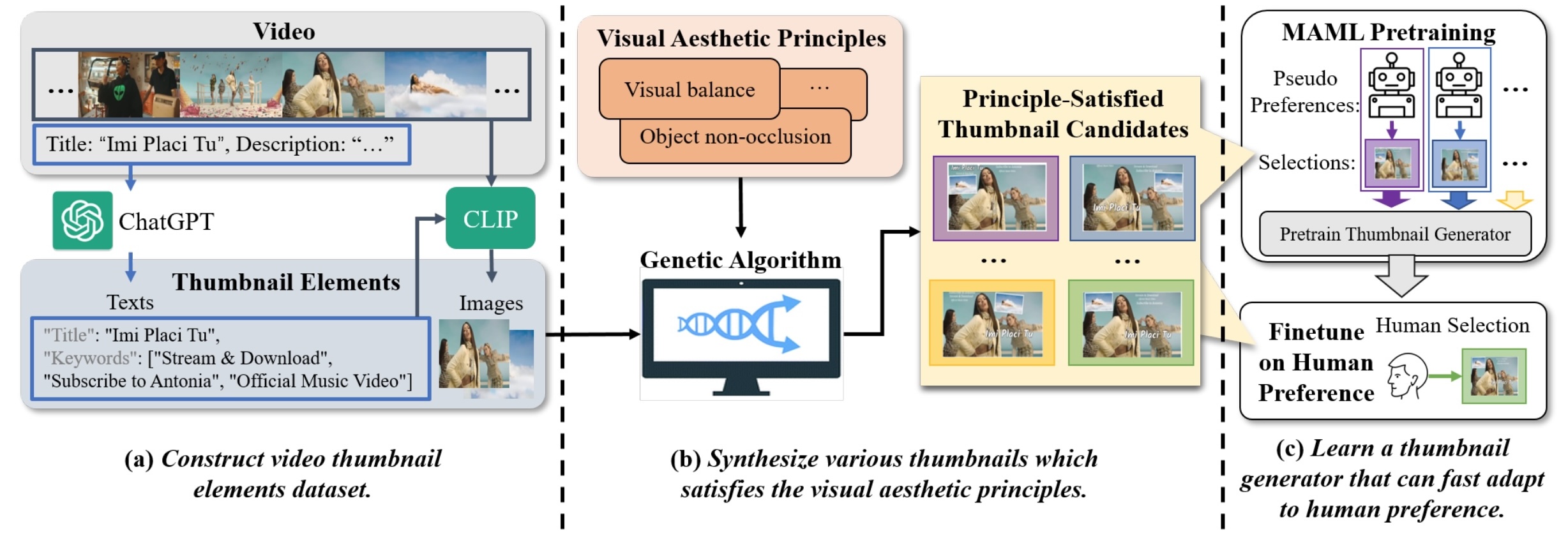
Video thumbnail plays an essential role in summarizing video content into a compact and concise image for users to browse efficiently. However, automatically generating attractive and informative video thumbnails remains an open problem due to the difficulty of formulating human aesthetic perception and the scarcity of paired training data. This work proposes a novel Human Perception-Centric Video Thumbnail Generation (HPCVTG) to address these challenges. Specifically, our framework first generates a set of thumbnails using a principle-based system, which conforms to established aesthetic and human perception principles, such as visual balance in the layout and avoiding overlapping elements. Then rather than designing from scratch, we ask human annotators to evaluate some of these thumbnails and select their preferred ones. A Transformer-based Variational Auto-Encoder (VAE) model is firstly pre-trained with Model-Agnostic Meta-Learning (MAML) and then fine-tuned on these human-selected thumbnails. The exploration of combining the MAML pre-training paradigm with human feedback in training can reduce human involvement and make the training process more efficient. Extensive experimental results show that our HPCVTG framework outperforms existing methods in objective and subjective evaluations, highlighting its potential to improve the user experience when browsing videos and inspire future research in human perception-centric content generation tasks.
PosterLLaVa: Constructing a Unified Multi-modal Layout Generator with LLM
[arXiv] [Code]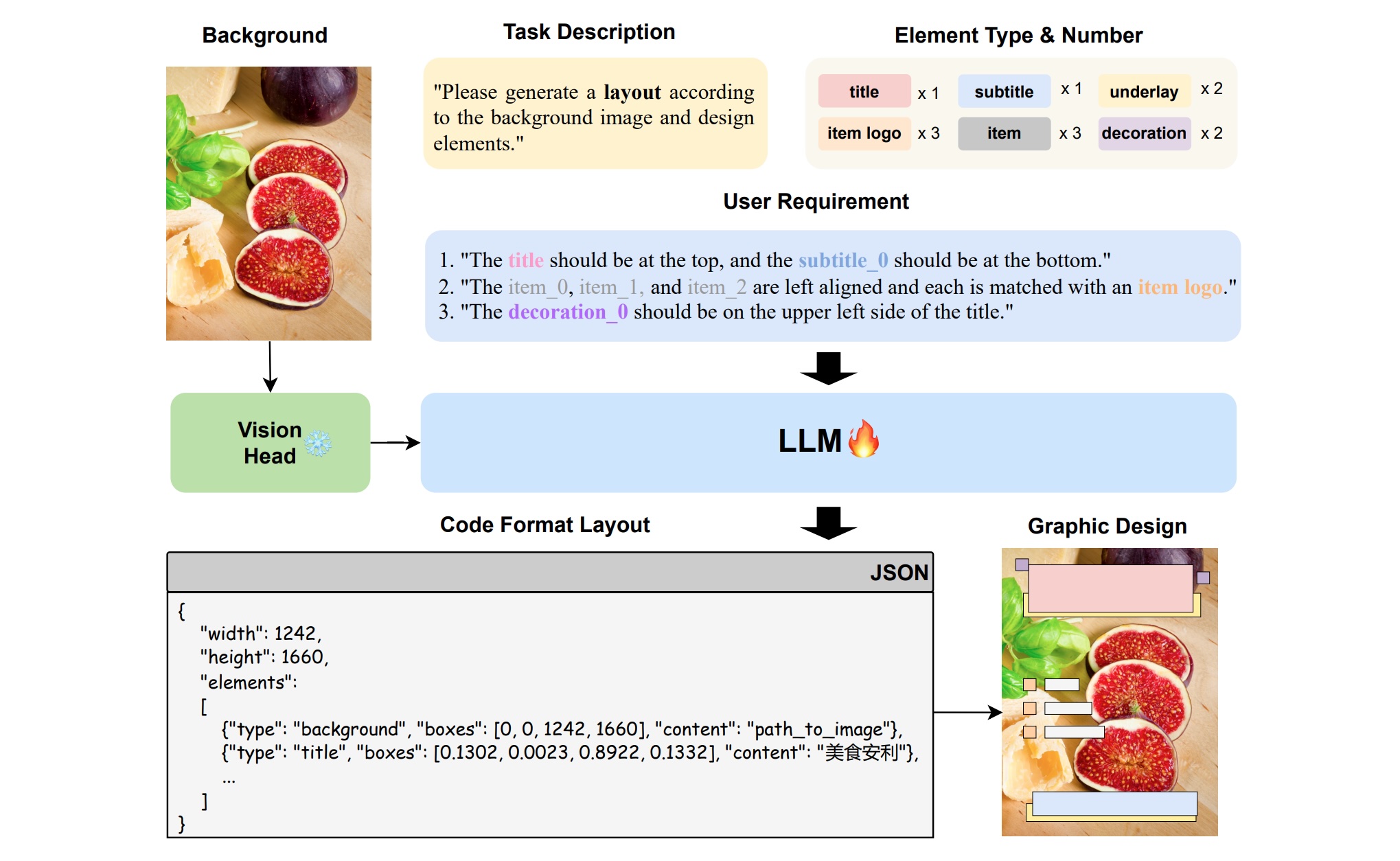
Layout generation is the keystone in achieving automated graphic design, requiring arranging the position and size of various multi-modal design elements in a visually pleasing and constraint-following manner. Previous approaches are either inefficient for large-scale applications or lack flexibility for varying design requirements. Our research introduces a unified framework for automated graphic layout generation, leveraging the multi-modal large language model (MLLM) to accommodate diverse design tasks. In contrast, our data-driven method employs structured text (JSON format) and visual instruction tuning to generate layouts under specific visual and textual constraints, including user-defined natural language specifications. We conducted extensive experiments and achieved state-of-the-art (SOTA) performance on public multi-modal layout generation benchmarks, demonstrating the effectiveness of our method. Moreover, recognizing existing datasets' limitations in capturing the complexity of real-world graphic designs, we propose two new datasets for much more challenging tasks (user-constrained generation and complicated poster), further validating our model's utility in real-life settings. Marking by its superior accessibility and adaptability, this approach further automates large-scale graphic design tasks.