Project #2: Image/Video Analytics
Video analytics encompasses broad ranges of research topics. Chen’s research team is working on three major topics:
- Human-Object Interaction (HOI) and Human-Human Interaction (HHI)
- Scene Graph Generation (SGG) from Images and Videos
- Storytelling from Images and Videos
These topics forms different but coherent levels of extracting semantics from images and videos. For human-object interaction, this is a constrainted analytic task that targets extracting from images and videos that contain human subject who are performing some type of action and interact with an object or thing. For scene graph generation, such image/video analytics task attempts to find out all types of objects, including human, and figure out their mutual relationship. The results from scene graph generation will generally represents a relatively complete description of all objects within an image or a video. Storytelling is certainly at a higher level of semantics extraction and is expected to be able to tell a coherent story based on the analytics performed on a given set of images and videos. All three research topics employ different deep learning techniques and also incoprorate common or prior knowledges as well as viusal perception principles to achieve enhanced analytics performance for numerous downstream AI tasks.
Human-Object Interaction (HOI) and Human-Human Interaction (HHI)
Many images and videos contains humans and associated objects. It is important to understand the interactions between human and objects as well as among human subjects within an image or a video. These two types of interaction are most fundamental for the computerized understanding of images and videos.

An illustration of knowledge-aware human-object interaction detection. Red, blue and black lines represent functionally similar objects, behaviorally similar actions and holistically similar interactions. We argue that successful detection of an HOI should benefit from knowledge obtained from similar objects, actions and interactions. The same philosophical argument can also be applied to human-human interaction to understant group activities when multiple human subjects are contained within an image or a video. Our approaches are based on how to incoporate knowledge into the detection and recognition of human-object interaction and human-human interaction.
Scene Graph Generation (SGG) from Images and Videos
Scene Graph Generation is another fundamental technique in image and video analytics. Scene graph is a structured representation of a scene that can clearly express the objects, attributes, and the relationships between objects in the scene. This is a higher level computer vision technique beyond simple object detection and recognition aiming at higher level of understanding and reasoning about visual scene. One important atrribute about the visual scene is the attention towards salient objects. To better generate scene graph, we believe the saliency attention mechnism will need to be embedded into the design SGG schemes. We have achieved an improved SGG results with the incorporation of saliency attention mechanism.
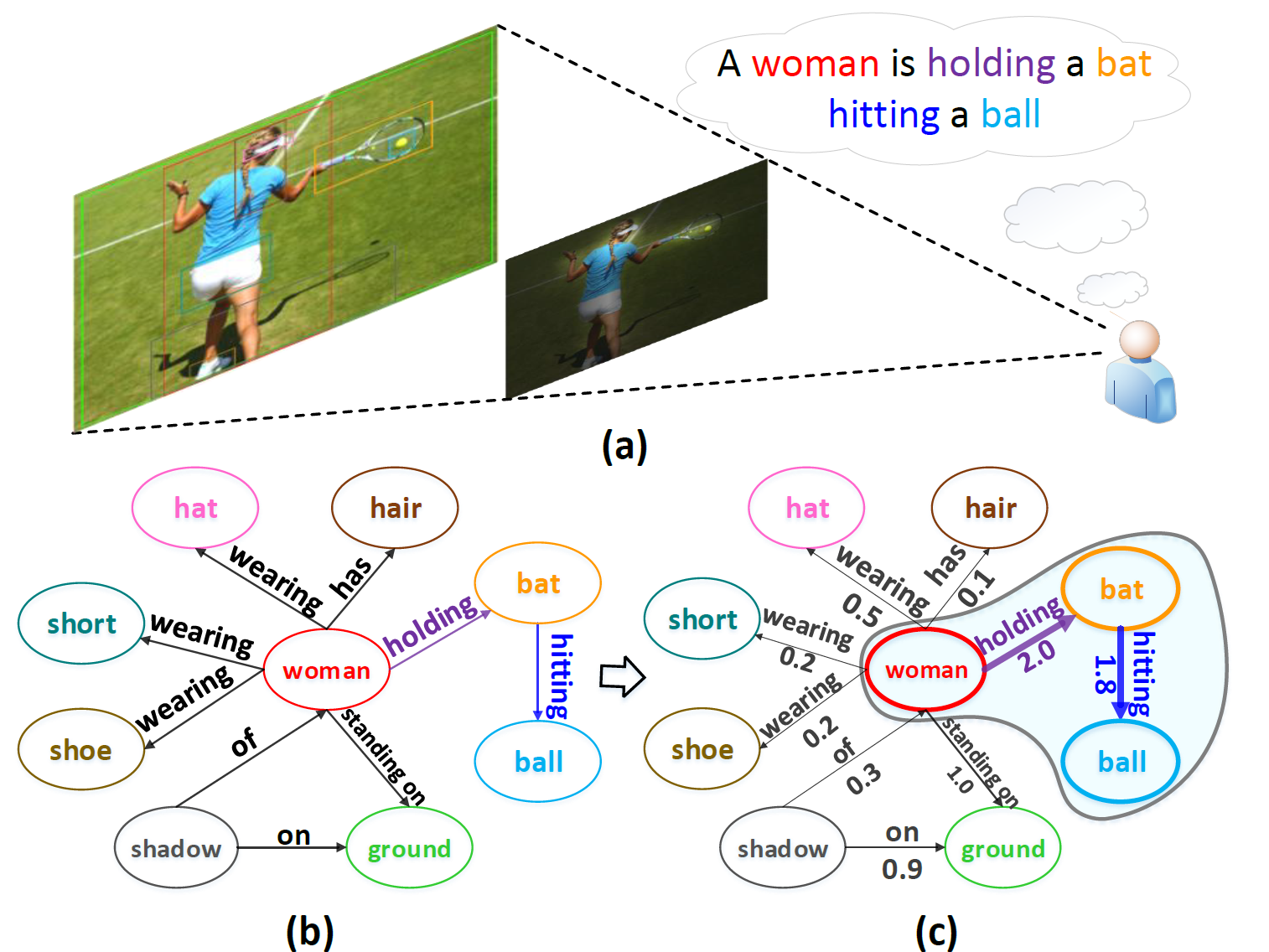
An illustration of human perception of a scene (a), where humans often allocate attention to the salient visual relations that are worthy of mention in a natural-language utterance. The existing scene graph generation schemes (b) fails to identify such salient relations, while the scene graph with key relations (c) better aligns with human perception by upgrading each edge with an attribute of relation saliency.
Storytelling from Images and Videos
Storytelling is certainly at a higher level of semantics extraction than human-object interaction, human-human interaction, and scene graph generation. This task is expected to be able to compose a coherent story based on the analytics performed on a given set of images and videos. In recent years, natural language description of a given image has achieved signficant advances with various image captioning approaches. Some of these dense captioning results can describe almost all subjects and objects within an image. Storytelling takes one step further to generated coherent paragraph of several sentences to tell a story that fully describes the theme of a set of related images or a segment of videos.

The above figure illustrations an example of visual storytelling result on SIND datasets. Three stories are generated for each photo stream: story by ground truth, story by baseline (by Park and Kim, NIPS2015) and story by the approach developed by Chen’s team implemented as Bidirectional Attention Recurrent Neural Networks (BARNN). The colored words indicate the semantic matches between the generation results against the ground truth. The proposed scheme shows better semantic alignment in storytelling.